在现代快递物流行业中,自动分拣系统是保证海量包裹高效、准确流转的核心枢纽。其运行一旦中断,将直接导致整个物流网络的阻塞与瘫痪,造成巨大的经济损失与客户信任危机。因此,构建一个具备高可用性与热备能力的数据处理及存储服务体系,不仅是技术需求,更是业务连续性的生命线。本文将深入探讨支撑快递物流自动分拣系统稳定运行的高可用热备解决方案,聚焦于其数据处理与存储服务的关键架构。
一、高可用热备的核心目标
对于自动分拣系统,高可用热备的目标是实现“业务零感知”的故障切换。具体而言:
- 数据零丢失:任何环节的故障都不能导致分拣指令、包裹路由信息、状态记录等关键数据的丢失。
- 服务不中断:主系统发生故障时,备用系统能瞬间(通常在秒级甚至毫秒级)接管,分拣线持续运转。
- 状态可恢复:切换后,新系统能完全继承故障前的所有处理上下文,确保每个包裹的路径连续性。
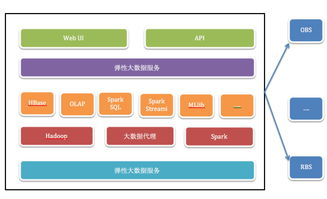
二、数据处理服务的高可用架构
分拣系统的数据处理服务负责解析订单、生成分拣指令、实时调度格口、反馈结果等,其高可用设计至关重要。
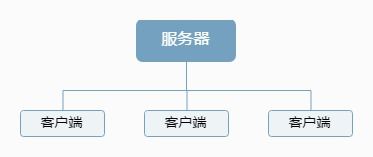
1. 无状态服务集群:
将核心业务逻辑(如路径计算、指令生成)封装为无状态服务模块。通过负载均衡器(如Nginx、F5)将请求分发至由多个实例组成的集群。任何单个实例故障,请求会被自动路由至健康实例,实现快速故障转移。
- 主从与多活部署:
- 主备模式(Active-Standby):主节点处理所有请求,备用节点实时同步主节点状态。通过心跳检测,一旦主节点失效,备用节点立即升为主节点。此模式切换迅速,但备用资源平时闲置。
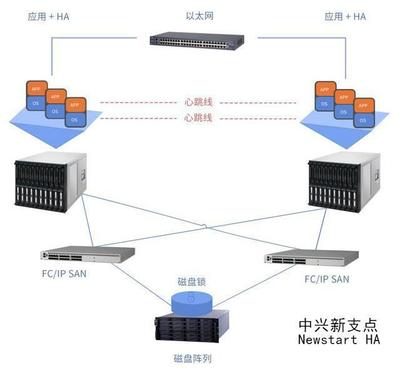
- 双活/多活模式(Active-Active):多个节点同时处理部分流量(如按分拣区域划分)。任一节点故障,其负载由其他节点接管。此模式资源利用率高,但对数据一致性要求极高,需复杂的流量调度与状态同步机制。物流分拣系统常采用“同城双活、异地灾备”的混合架构。
3. 消息队列解耦与持久化:
使用高可用的消息中间件(如Kafka、RocketMQ)作为各服务模块间的通信总线。分拣指令、扫描事件等消息被持久化存储,即使消费服务暂时宕机,消息也不会丢失,重启后可继续处理,保证了数据流的不间断与可回溯。
三、数据存储服务的高可用与热备策略
分拣系统产生的数据包括结构化数据(订单、路由关系)和非结构化数据(包裹面单图片、监控视频),其存储必须万无一失。
- 数据库层高可用:
- 关系型数据库:采用主从复制(如MySQL Replication)或集群方案(如MySQL Cluster, PostgreSQL流复制)。结合读写分离,主库负责写入,从库提供读服务与热备。利用中间件或代理实现故障时的自动主从切换。
- 分布式NoSQL数据库:对于海量路由规则、缓存数据,可选用原生支持高可用的分布式数据库(如MongoDB副本集、Cassandra)。数据自动在多节点间复制,任一节点故障不影响整体服务。
- 存储冗余与实时同步:
- 本地冗余(RAID)与存储网络:采用RAID阵列防止单块磁盘故障,并通过SAN(存储区域网络)提供稳定、高性能的共享存储,支持服务器快速挂载与切换。
- 异地容灾与数据同步:在异地灾备中心部署一套完整的存储系统。通过存储层同步技术(如异步/同步复制)或数据库级的主从复制,将生产中心数据近乎实时地复制至灾备中心。确保在主数据中心发生重大故障时,能快速启用灾备系统。
3. 数据备份与快速还原:
高可用热备解决的是“连续性”问题,备份解决的是“可恢复性”问题。必须实施定期的全量备份与增量备份,并将备份数据存储在物理隔离的安全位置。定期进行灾难恢复演练,验证备份数据的完整性和恢复流程的时效性,确保在极端情况下能在规定时间内(RTO)将数据恢复到指定时点(RPO)。
四、关键技术保障与监控
- 虚拟化与容器化:采用VMware、KVM或Docker+Kubernetes平台,可以实现计算资源的快速迁移与弹性伸缩。当物理服务器故障时,虚拟机或容器可在集群内其他节点迅速重启,极大缩短恢复时间。
- 统一监控与智能告警:构建覆盖应用、服务、数据库、服务器、网络的全链路监控体系(如Prometheus + Grafana, Zabbix)。对关键指标(如服务响应时间、队列堆积、数据库连接数、同步延迟)设置阈值,实现故障的提前预警与自动定位,为主动切换和快速排障提供支持。
###
快递物流自动分拣系统的高可用热备建设,核心在于其数据处理与存储服务的冗余设计、快速切换与数据一致性保障。它不是一个孤立的技术点,而是一套从应用架构到基础设施,从本地集群到异地灾备的立体化、体系化工程。通过融合集群化部署、数据实时同步、消息解耦与智能监控等关键技术,才能构建起真正意义上“永不掉线”的智能分拣中枢,支撑起现代物流高效、可靠运转的脊梁。