在数字化产品竞争日益激烈的今天,构建一套高效、可靠的数据运营体系已成为企业提升产品力、优化用户体验、驱动业务增长的核心引擎。腾讯、YY语音和迅雷等互联网巨头,凭借其丰富的产品矩阵和海量用户实践,在数据处理与存储服务领域积累了宝贵的经验。本文将梳理并解读其共同践行的11步关键路径,为构建稳健的产品数据运营体系提供实战参考。
第一步:明确数据战略与业务目标对齐
数据运营不是无源之水。腾讯强调,数据体系构建之初,必须与公司及产品的核心战略、关键业务目标(如用户增长、活跃度、营收提升)紧密对齐。YY语音在初期便明确了通过数据分析驱动社区生态繁荣和主播变现的目标,使数据收集、处理有的放矢。
第二步:规划全域数据采集与埋点体系
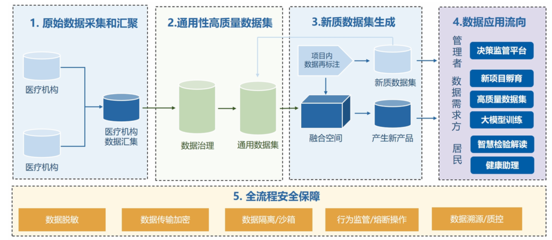
全面、准确、规范的数据是基础。迅雷在下载业务中,建立了覆盖用户端、服务端、业务日志的全方位埋点体系,确保关键用户行为、性能指标、业务状态无一遗漏。腾讯则推行统一的埋点规范与管理平台,保障数据口径一致,减少后续治理成本。
第三步:构建弹性可扩展的数据接入层
面对海量、异构、实时涌入的数据流,需要强大的接入能力。YY语音采用高可用的消息队列(如Kafka集群)作为数据总线,实现业务数据与日志数据的异步、缓冲接入,应对峰值流量,确保数据不丢失。
第四步:设计分层分域的数据存储架构
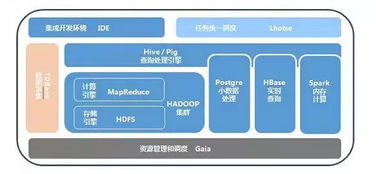
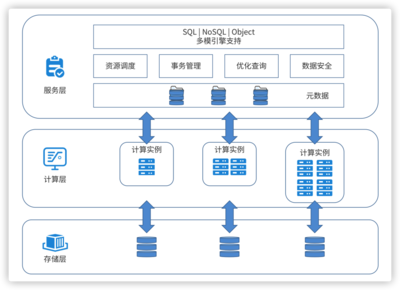
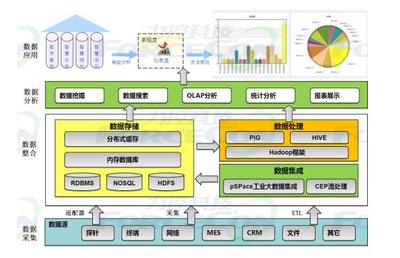
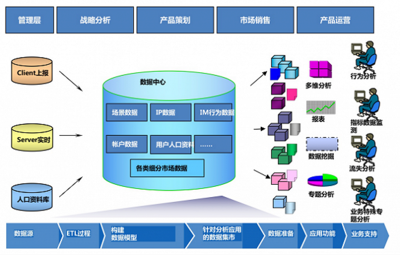
根据数据热度、使用场景和成本,选择差异化存储方案。通用实践是构建“原始数据层-明细数据层-汇总数据层-应用数据层”的梯级存储。腾讯将实时热数据存入高速NoSQL(如Redis),明细数据入分布式数据仓库(如Hive/HDFS),聚合结果与维度表入关系型数据库或OLAP引擎(如ClickHouse),兼顾性能与深度分析。
第五步:实施高效可靠的数据处理与计算
数据处理包括离线批处理与实时流处理。迅雷利用Hadoop/Spark生态进行大规模的离线ETL(提取、转换、加载),清洗、关联原始数据,生成规整的数据集市。对于实时监控和即时反馈场景(如推荐、风控),采用Flink等流计算框架进行低延迟处理,YY语音在实时互动场景中便深度依赖于此。
第六步:建立统一的数据资产管理与治理
数据成为资产,必须有效管理。腾讯数据中台的核心之一是数据资产地图,对数据表、指标、标签进行全域血缘追踪、质量监控和权限管控。建立数据标准、保障数据安全与合规(如GDPR),是可持续运营的基石。
第七步:搭建敏捷的数据服务与API化
将数据能力以服务形式开放,赋能业务。通过构建统一的数据服务层,将复杂的查询、模型计算结果封装成标准API,供产品端、运营后台、分析系统调用。迅雷和YY语音都通过API网关,高效、安全地向内部各团队提供用户画像、行为分析等数据服务。
第八步:部署智能化的数据分析与挖掘平台
为分析师和业务人员提供自助分析工具(如BI平台),降低数据使用门槛。搭建机器学习平台,支持特征工程、模型训练与部署,实现从描述性分析到预测性、指导性分析的飞跃。腾讯在此领域投入巨大,以支撑其精准营销和内容推荐等智能业务。
第九步:实现产品端的实时反馈与个性化应用
数据价值最终体现在产品端。通过将处理后的数据、用户标签、模型评分实时反馈给产品客户端或推荐引擎,实现千人千面的内容分发、个性化提示、智能客服等,直接提升用户体验和转化率,这是YY语音运营直播房间、腾讯运营内容生态的关键环节。
第十步:建立闭环的数据驱动决策与运营流程
将数据分析洞察融入产品迭代和运营活动全生命周期。通过A/B测试平台验证想法,监控核心数据看板评估效果,形成“假设-实验-分析-迭代”的闭环。迅雷在下载加速策略优化中,便严格遵循这一数据驱动的实验文化。
第十一步:持续监控、优化与成本效能评估
数据体系需要持续运营和维护。监控数据管道健康度、任务时效、存储与计算资源消耗。在保障稳定性的通过技术优化(如数据压缩、计算资源调度、冷热数据分离)和架构演进,不断平衡成本、性能与业务价值,确保数据运营体系长期高效、经济地运转。
****
构建产品数据运营体系是一项系统工程,上述11步环环相扣,从顶层设计到底层技术,从数据生产到价值消费。腾讯、YY语音和迅雷的实践表明,成功的体系源于技术与业务的深度融合,以及持续迭代的运营思维。关键在于以业务价值为导向,以可靠的数据处理与存储服务为基石,最终打造出能够敏锐感知用户、快速响应市场、智能驱动增长的强大数据引擎。